Virtual Warehouse คืออะไร: หน่วย compute ของ Snowflake ที่มักเข้าใจผิด
เช้าวันจันทร์ คุณเปิดหน้า usage ของ Snowflake ขึ้นมาดู credit ประจำสัปดาห์ แล้วสายตาไปสะดุดกับกราฟแท่งหนึ่งที่สูงผิดปกติ พาดยาวข้ามทั้งเสาร์อาทิตย์ พอคลิกเข้าไปดูถึงรู้ว่า warehouse ตัวที่ทีมเปิดไว้รัน transformation ตอนบ่ายวันศุกร์ไม่เคยถูกปิดเลย มันรันค้างมาสองวันเต็มทั้งที่ไม่มี query สักตัววิ่งเข้าไป แต่ก็กิน credit ทุกวินาที เรื่องแบบนี้เกิดขึ้นจริงในทีม data ทั่วโลก และต้นเหตุของมันมักมาจากความเข้าใจผิดเรื่องเดียว นั่นคือ “virtual warehouse คืออะไรกันแน่”
“warehouse” ที่ไม่ได้เก็บอะไรเลย
คำว่า warehouse ชวนให้นึกถึงโกดังเก็บของ แต่ใน Snowflake มันตรงข้ามกับที่ชื่อบอกเลย virtual warehouse คือหน่วย compute — กลุ่มของพลังประมวลผล (compute cluster) ที่คุณเปิด ปิด และปรับขนาดได้ตามต้องการ หน้าที่ของมันคือ “ทำงานจริง” ได้แก่ รัน SELECT, ทำ DML อย่าง insert/update/delete และ load ข้อมูลเข้า table
สิ่งที่มันไม่ได้ทำคือเก็บข้อมูล data จริง ๆ ทั้งหมดอยู่ในชั้น storage แยกต่างหาก virtual warehouse แค่เข้าไปอ่านหรือเขียนข้อมูลก้อนนั้นเวลามีงาน ถ้าใครถามว่า warehouse ทำหน้าที่อะไร คำตอบที่ถูกคือ “execute SQL / DML / load data” ไม่ใช่ “เก็บข้อมูล”
virtual warehouse = compute เท่านั้น ไม่ใช่ที่เก็บ data และไม่ใช่ database — จำประโยคนี้ไว้ แล้วครึ่งหนึ่งของความสับสนเรื่อง Snowflake จะหายไป
มีจุดที่ช่วยตอกย้ำเรื่องนี้: งานที่เป็นแค่การถาม metadata เช่น SHOW TABLES, DESCRIBE TABLE หรือ DDL อย่าง CREATE TABLE รันได้ทันทีโดยไม่ต้องเปิด warehouse เลย เพราะมันไม่ต้องไปแตะ data จริง แต่พอเป็น SELECT, COPY INTO หรือ DML เมื่อไร ต้องมี warehouse เปิดอยู่เสมอ เพราะงานพวกนี้ต้องอ่าน/เขียนข้อมูลจริง
ทีมงานที่มีพลังของตัวเอง
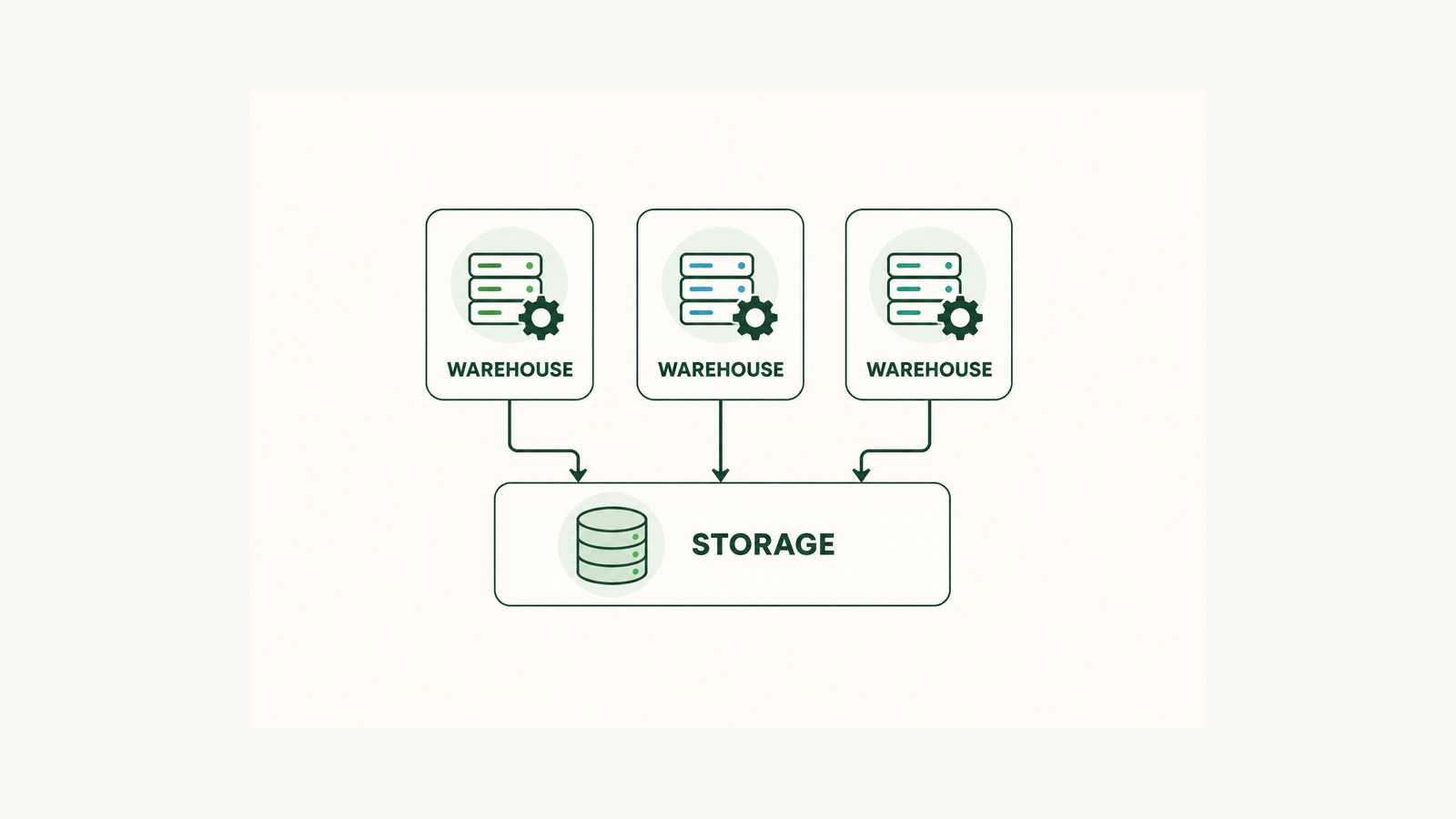
หัวใจของ Snowflake คือการแยก storage ออกจาก compute อย่างเด็ดขาด data ทั้งหมดอยู่ในที่เก็บกลางก้อนเดียวที่ทุก warehouse มองเห็นเหมือนกัน แต่พลังประมวลผลแยกเป็นของใครของมัน นี่คือเหตุผลที่ Snowflake ทำหลายอย่างที่ฐานข้อมูลแบบเดิมทำไม่ได้
แต่ละ virtual warehouse เป็น compute cluster อิสระ ไม่แชร์ resource กับ warehouse ตัวอื่น
ผลที่ตามมาคือสิ่งที่มีประโยชน์มากในงานจริง เพื่อนคุณรัน dashboard query หนัก ๆ บน warehouse ตัวหนึ่ง คุณรัน query ของคุณบนอีกตัวหนึ่ง ทั้งสองอ่าน data จากที่เก็บกลางเดียวกัน แต่ใช้พลัง compute คนละก้อน เลยไม่แย่งทรัพยากรกัน หลายองค์กรจึงตั้ง warehouse แยกตามทีมหรือตามงาน เช่น WH_LOADING สำหรับโหลดข้อมูล, WH_ANALYTICS สำหรับ dashboard, WH_ML สำหรับงานโมเดล
แต่มีกับดักที่ทั้งข้อสอบและงานจริงชอบหลอก — isolation นี้อยู่ ระหว่าง warehouse ไม่ใช่ระหว่างคนที่ใช้ warehouse เดียวกัน ถ้าคุณกับเพื่อนใช้ warehouse ตัวเดียวกัน ก็ยังต้องแบ่ง compute ในตัวนั้นกันอยู่ดี การแยกงานหนักออกจากกันจึงต้องแยกที่ตัว warehouse ไม่ใช่แค่แยก user
เปิดอยู่ = จ่ายเงิน แม้ไม่มีงาน
กลับมาที่บิลพุ่งตอนต้นเรื่อง กุญแจของมันอยู่ที่ state ของ warehouse ซึ่งมีอยู่ 4 สถานะ
- Started — เปิดอยู่พร้อมรับงาน และกิน credit ตลอดเวลา แม้ไม่มี query สักตัววิ่ง
- Suspended — พักอยู่ ไม่กิน credit เลย (0 credits)
- Resuming — กำลังเปิดขึ้นมา ใช้เวลาแค่ไม่กี่วินาที
- Quiesce — กำลังจะพัก แต่รอ query ที่รันค้างอยู่ให้เสร็จก่อน
จำประโยคเดียวก็พอ — Started = กินเงิน, Suspended = ฟรี เคสบิลพุ่งตอนเปิดเรื่องไม่ได้เกิดเพราะมีใครรัน query หนัก แต่เพราะ warehouse ค้างอยู่ที่ Started ทั้งสุดสัปดาห์ ลองคิดเล่น ๆ ตามอัตราที่เราจะดูกันต่อ — X-Large กิน 16 credits ต่อชั่วโมง คูณ 48 ชั่วโมงโดยประมาณ ก็ราว ๆ 768 credits ที่ละลายไปกับการเปิดเครื่องเปล่า ๆ โดยไม่ได้งานอะไรกลับมาเลย ทางแก้คือคำเดียวที่คนลืมบ่อยที่สุด นั่นคือตั้ง auto-suspend ให้ warehouse พักเองเมื่อว่างถึงเวลาที่กำหนด
ขนาดที่คูณสองไปเรื่อย ๆ
virtual warehouse มีหลายขนาด ตั้งแต่ X-Small ขึ้นไปจนถึง 6X-Large กติกาที่ทำให้จำง่ายคือ ทุกครั้งที่ขยับขึ้นหนึ่งขนาด credit ต่อชั่วโมงจะเพิ่มเป็นสองเท่า และ (ตามทฤษฎี) พลังประมวลผลก็เพิ่มประมาณสองเท่าตามไปด้วย เริ่มจาก X-Small = 1 credit/ชั่วโมง แล้วคูณสองไปเรื่อย ๆ คือ 1, 2, 4, 8, 16 … เห็นรูปแบบแล้วก็ไล่ต่อได้เองโดยไม่ต้องท่อง
อีกจุดที่สำคัญเรื่องการคิดเงิน Snowflake คิดแบบ per-second (ต่อวินาที) แต่มี ขั้นต่ำ 60 วินาที ทุกครั้งที่ warehouse start หรือ resume แปลว่าถ้าคุณ resume warehouse ขึ้นมารัน query เล็ก ๆ ที่เสร็จใน 5 วินาที คุณก็ยังถูกคิด 60 วินาทีอยู่ดี เหมือนค่าน้ำขั้นต่ำ ใช้นิดเดียวก็จ่ายเท่าขั้นต่ำ จุดนี้คือเหตุผลที่การตั้ง auto-suspend สั้นเกินไปจนเปิด-ปิดถี่ ๆ ก็ไม่ได้ประหยัดอย่างที่คิด
ใหญ่ขึ้นไม่ได้แปลว่าเร็วขึ้นเสมอ
พอรู้ว่าขนาดใหญ่ขึ้นแพงขึ้น คำถามต่อไปคือ “เมื่อไรควรขยาย และขยายแบบไหน” ตรงนี้มีสองคำที่ฟังดูคล้ายกันจนสับสน แต่แก้คนละปัญหา
Scale up คือการขยายขนาด (เช่น Medium → X-Large) เปรียบเหมือนทีมเดิมแต่แต่ละคนแข็งแรงขึ้น ยกของหนักได้มากขึ้น ใช้แก้ปัญหา query เดียวที่หนัก ซับซ้อน หรือ scan ข้อมูลมหาศาลแล้วช้า ส่วน Scale out คือการเพิ่มจำนวน cluster ผ่าน multi-cluster warehouse (เช่น 1 cluster เป็น 3 cluster ขนาดเท่าเดิม) ไม่ได้ทำให้แต่ละทีมแข็งแรงขึ้น แต่เพิ่มจำนวนทีมเข้ามารับงาน ใช้แก้ปัญหา concurrency คือมีคนรัน query พร้อมกันเยอะจนต้องเข้าคิว
scale up แก้ query ช้า · scale out แก้ user เยอะ
ลองเทียบกับเคาน์เตอร์รับลูกค้า ถ้าแคชเชียร์คนเดียวทำงานช้าเพราะออเดอร์ซับซ้อน คุณต้องหาคนที่เก่งกว่ามาแทน (scale up) แต่ถ้าลูกค้าต่อแถวยาวเพราะคนเยอะ คุณต้องเปิดเคาน์เตอร์เพิ่ม (scale out) — และการเปิดเคาน์เตอร์เพิ่มไม่ได้ทำให้แคชเชียร์แต่ละคนทำงานเร็วขึ้นเลย เพราะฉะนั้น multi-cluster จึงไม่ได้ช่วยให้ query เดียวเร็วขึ้น มันช่วยเรื่องคนเยอะพร้อมกันเท่านั้น และอย่าลืมว่าขนาดที่ใหญ่ขึ้นก็ไม่ได้ทำให้ query ง่าย ๆ เร็วขึ้นเสมอ ถ้าคอขวดไม่ได้อยู่ที่ compute การจ่าย credit เพิ่มเป็นสองเท่าก็อาจได้ความเร็วเพิ่มมาแค่นิดเดียว วิธีที่ถูกคือทดสอบ query เดิมบนหลายขนาดแล้วเทียบเวลากับ credit ก่อนตัดสินใจ
warehouse คือทีมที่จ้างเป็นรายวินาที
ถ้าจะสรุป virtual warehouse ให้เหลือภาพเดียว ให้คิดว่ามันคือทีมพนักงานที่จ้างเป็นรายวินาที พอมีงานก็เรียกมา (resume) พอหมดงานก็ส่งกลับบ้าน (suspend) แล้วหยุดจ่ายค่าแรง ความเข้าใจผิดทั้งหมดที่ทำให้บิลพุ่งล้วนมาจากการลืมว่า “ทีมงานยังนั่งรออยู่” ทั้งที่ไม่มีงานแล้ว
พอแยกออกสามเรื่อง — warehouse คือ compute ไม่ใช่ที่เก็บข้อมูล, เปิดอยู่คือจ่ายเงินไม่ว่าจะมีงานหรือไม่, และเลือก scale ให้ตรงกับปัญหาว่า “ช้า” หรือ “คิวยาว” — คุณก็จะคุมได้ทั้ง performance และ cost ไปพร้อมกัน ซึ่งสุดท้ายแล้วนั่นคือทักษะที่ทำให้คนทำงานสาย data ดูแลระบบบนคลาวด์ได้โดยไม่ต้องลุ้นบิลทุกเช้าวันจันทร์